System Demonstration
01. The Problem
The global translation industry has a hidden technical debt: Layout Entropy.
Standard OCR tools (AWS Textract, Tesseract) treat documents as unstructured "bags of words." While they extract text efficiently, they fail to preserve layout topology—breaking tables, merging headers, and displacing stamps.
Sworn translators save 60 minutes on translation but lose 45 minutes per document manually reconstructing formatting in Microsoft Word.
The Solution: I architected Verto, a proprietary reconstruction engine. It does not just "read" text; it rebuilds the document's DOM with high structural fidelity in native Google Docs.

02. Architecture
The system is designed as an event-driven, stateful reconstruction pipeline. It prioritizes Durable Execution over simple request/response cycles.
A. The Auditor
Generating JSON is easy; guaranteeing legal accuracy is hard. I implemented an Adversarial Verification Loop (Agent 2) that challenges the output of the reconstruction engine (Agent 1).
- Agent 1 (Builder): Generates the document DOM based on visual input.
- Agent 2 (Auditor): Performs geometric and visual consistency checks against the source image.
- The Loop: If the Auditor detects a missing stamp or misaligned table border, it rejects the batch and forces a regeneration with higher attention weights on the failed region.
Result: A self-correcting pipeline that prioritizes accuracy over speed, crucial for the "Sworn Translation" market.
B. The Google Docs Bridge
The Google Docs API allows for programmatic document creation but requires strictly ordered batchUpdate requests. It does not accept HTML or raw text dumps.
I engineered a custom Intermediate Representation (IR) mapper (GoogleDocsMapper) that translates the AI's ProseMirror AST into specific Google Docs operations.
Core Challenge: Virtual Grid Calculation
Google Docs tables cannot be pasted; they must be constructed cell-by-cell. To handle complex legal tables with merged cells (rowspan/colspan), the system must "simulate" the table in memory before writing it.
// src/lib/google-docs/mapper/virtual-grid.ts
// Complexity: O(n*m) where n=rows, m=cols.
// Core Logic: Resolving the Virtual Grid for Table Reconstruction
// This ensures high structural fidelity for complex legal tables.
for (let r = 0; r < node.content.length; r++) {
for (const cell of row.content) {
// Check collision with previous rowspan/colspan
while (grid[r] && grid[r][c]) {
c++;
}
// Register span for later API merge requests
if (colspan > 1 || rowspan > 1) {
spanMap.set(`${r},${c}`, { row: r, col: c, rowspan, colspan });
}
}
}
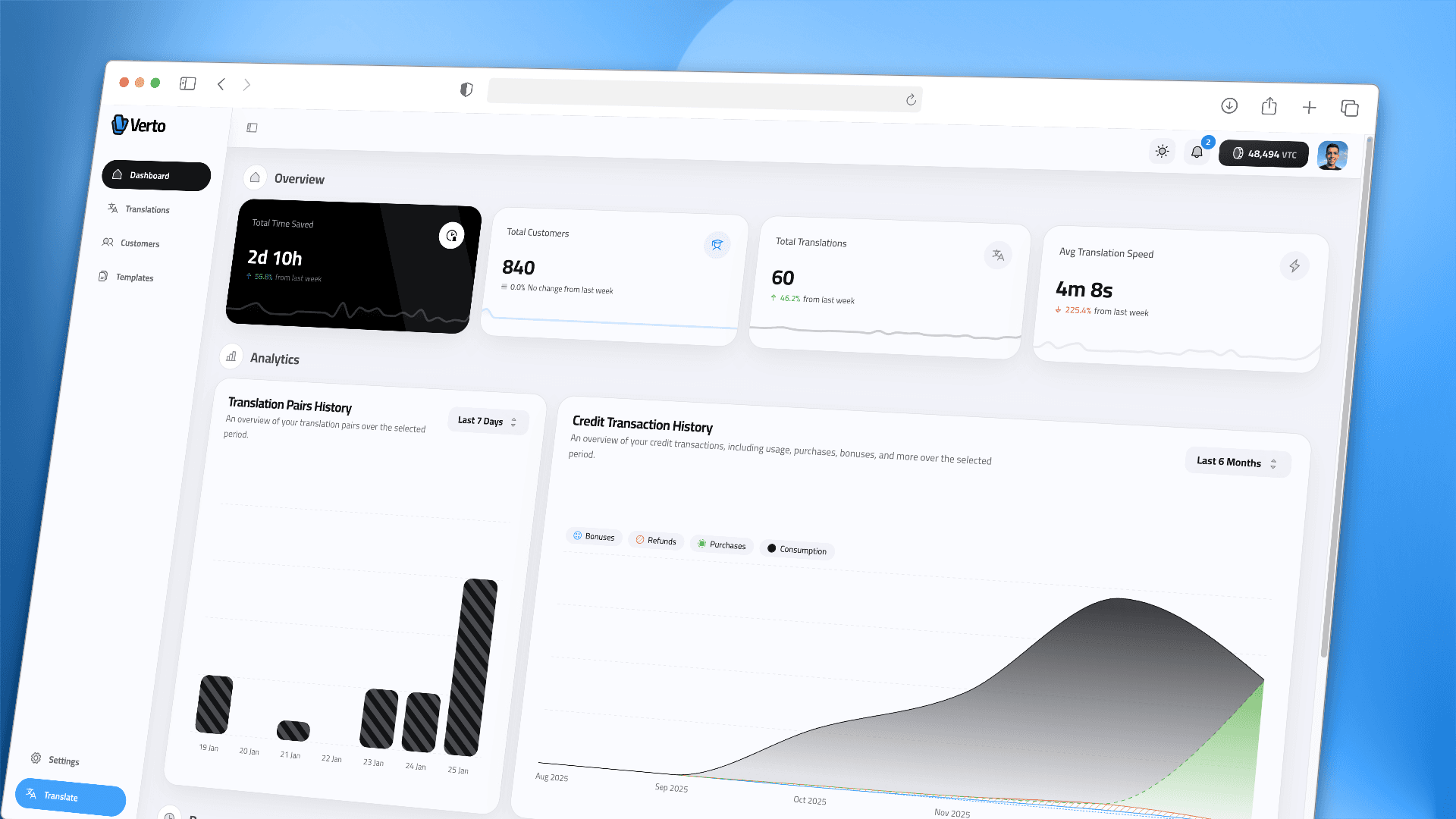

C. Processing Pipeline
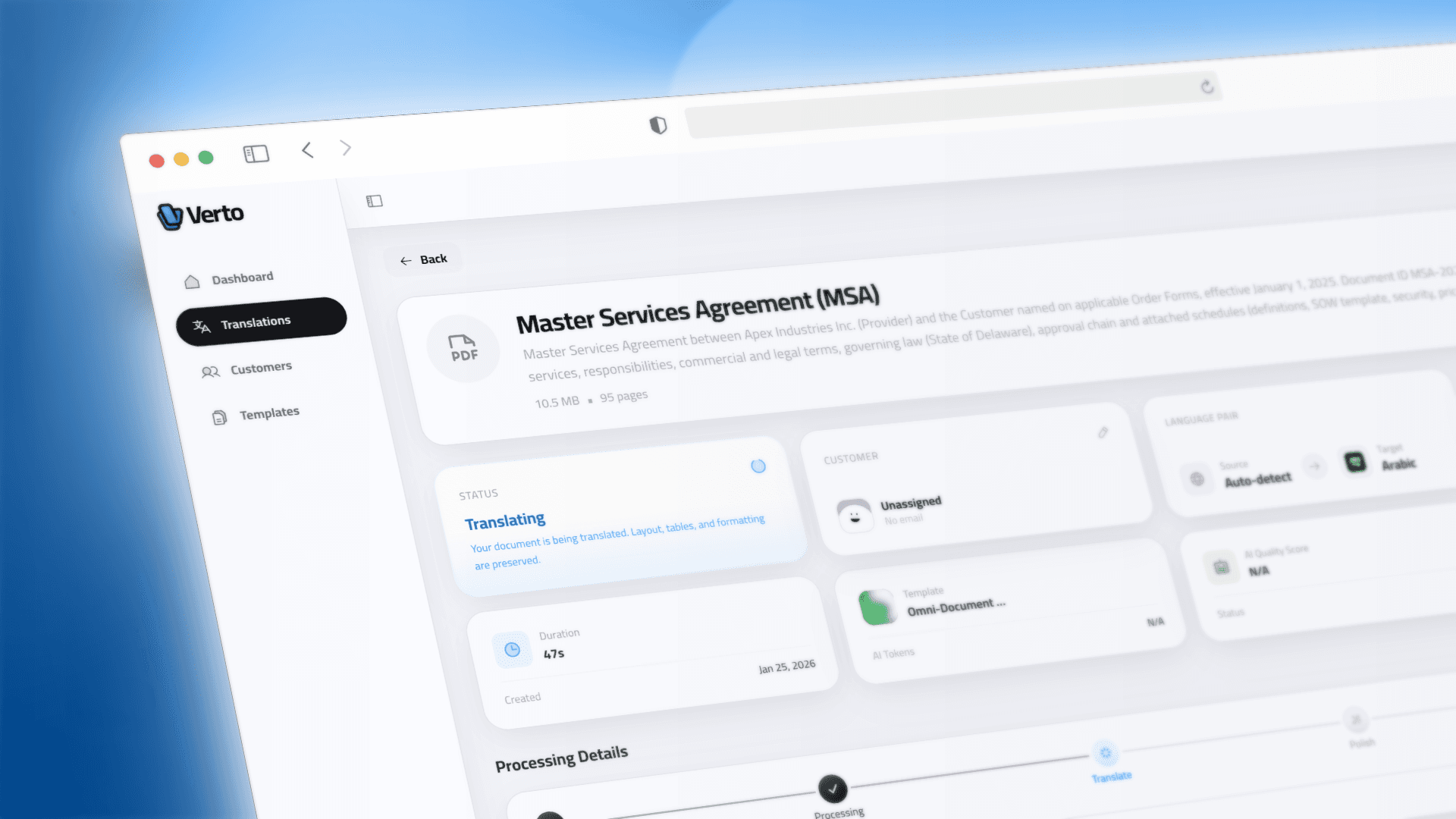
Processing 50+ page discovery files exceeds standard context windows. I implemented a Rolling Context State Machine that passes a BatchContext object between execution steps, enforcing semantic consistency across the entire file lifecycle.
The compute layer runs on Trigger.dev to achieve Durable Execution. If a job fails on Page 45, the system resumes from the last committed checkpoint rather than restarting.
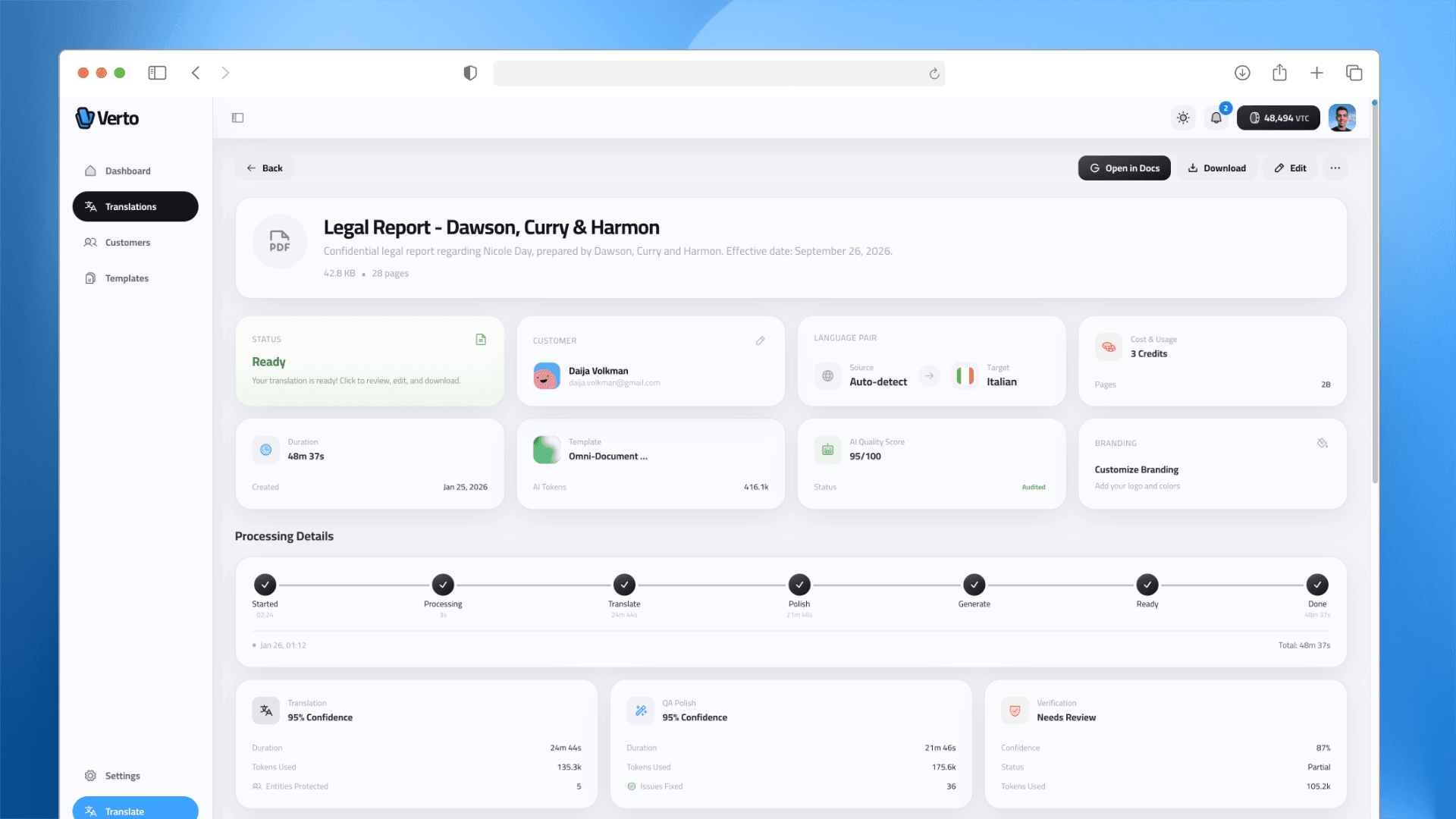
03. Infrastructure
The Double-Entry Ledger
To handle the "Per-Page" credit system, I rejected simple database increments. I implemented a Double-Entry Ledger in PostgreSQL.
- ACID Compliance: Every credit consumption is a transaction row, not a field update.
- Race Condition Proof: This architecture guarantees financial accuracy even when multiple heavy documents finish processing simultaneously.
04. Capability
Verto is fully functional and architected to solve the "Layout Entropy" problem for real-world legal documents. It is currently available as a white-label engine for translation agencies.
| Metric | Standard OCR | Verto Engine |
|---|---|---|
| Table Accuracy | < 60% (Breaks on merges) | High Fidelity (Virtual Grid Verified) |
| Formatting Time | 45 Minutes / Doc | < 2 Minutes (Review Only) |
| Job Completion Rate | ~85% (Timeouts on large files) | 99.9% (Durable Execution) |
| Output | Static PDF | Native, Editable Google Doc |
05. Tech Stack
This platform required a deep integration of Event-Driven Architecture and Modern Frontend Constraints.
| Domain | Core Stack | Key Libraries & Patterns |
|---|---|---|
| Frontend | Next.js 16 | React Server Components, Server Actions, Edge Runtime. |
| UI System | Tailwind v4 | shadcn/ui (Radix Primitives), framer-motion (Layout Constraints), sonner (Toast System). |
| Editor | Tiptap | Headless ProseMirror implementation with Custom Node Views (React NodeView). |
| State | TanStack Query | Optimistic UI updates synchronized via Supabase Realtime (WebSockets). |
| Compute | Trigger.dev | Long-running background jobs (24h max duration) on dedicated containers. |
| Validation | Zod | Strict schema validation for AI Structured Outputs (openai.responses). |
| Data Viz | Recharts | Interactive credit consumption and burn-down analytics. |
| PDF Engine | React-PDF | Virtualized PDF rendering with react-window for large legal files. |
| Payments | Stripe | Webhook-driven Ledger synchronization with Idempotency keys. |
06. Thesis
Verto proves that solving "Layout Entropy" requires treating documents as Stateful Systems, not static assets.
The value isn't in the AI model (which is a commodity); it is in the Bridge that makes that model compatible with the rigid constraints of the real world (Google Docs, Legal Compliance, Auditors).
This project wasn't just about building a translation tool; it was about engineering a Visual Compiler that turns raw pixels into structured, legally binding data.